Data Layer : Android app architecture notes
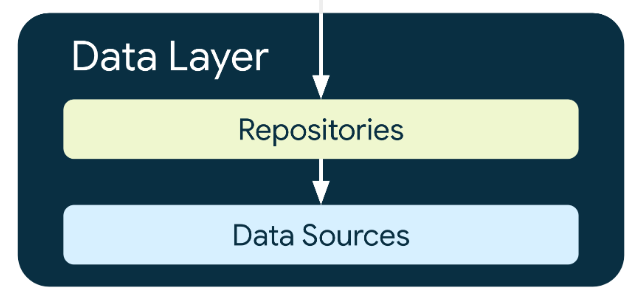
This contains the application data and business logic and rules that determine how CRUD can be performed in the app. The separation of concern achieved thorough the DataLayer enables it to be used in multiple screens, share information between multiple parts of the app and also reproduce business logic outside of the app for testing. It consists of repositories where each can contain zero to multiple data sources. You should create a repository for each data type handled within your app.
Roles
- Exposing data to the rest of the app.
- Centralizing data changes.
- Resolving conflicts between multiple data sources.
- Contains business logic.
- Abstracting data sources from the rest of the app.
Each data source class should only be responsible for working with only a single source of data which can be a file, database or network source.
Complex operations are performed in the data layer to encourage reusability and caching.
Data source classes bridge between your app and the system for data operations. Other layers are never supposed to directly access the data layer and the only entry points to the data layer should be through repository classes. This allows the different layers to scale independently.
Data emmited by the data layer should be immutable.
Repository classes take data sources as dependencies.
class TodoItemsRepository(
private val remoteDataSource: RemoteDatasource,
private val localDataSource: LocalDataSOurce
){
// functions that expose immutable data to other layers
}Usually when a repository makes use of a single data source and is not dependent on other repositories, developers usually combine the role of the repository and the data source into the repository class.
Exposing Data Layer APIs
Repository classes usually expose functions to perform one shot CRUD (Create, Read, Update, Delete) operations or to be notified of data changes over time.
The data layer exposes the following APIs to UseCases;
- One shot suspending operations that perform CRUD operations on the database.
- Kotlin
flowsto notify the other layers on changes on the data.
class ExampleRepository(
//dependencies
){
val exampleData: Flow<DataType> = //...
suspend fun modifyData(parameter: Parameter){
//...
}
}Repository naming convention
name of data type + Repository
//for example
NewsRepository
AuthorsRepository
PaymentsRepositoryData source classes are named after the type of data + type of source + DataSource
//for example
NewsRemoteDataSource
NewsLocalDataSourceRepositories using a data should not know how that data is stored. Such that you can shift the implementation of the source of the data without affecting the other layers.
Sometimes repositories will depend on other repositories especially when you need to aggregate data from different repositories.

Data exposed from the repositories should always be data coming from a single source of truth. The single source of truth should always be accurate, correct and up to date.
The data source can be a database or a repository cache, the repositories are always solving conflicts between multiple data sources to update the single source of truth usually as a response to user interactions or changes in the data sources.
In order to build offline first apps, a local database is the recommended source of truth. While using firebase, you can use the firebase persistence to enable offline caching of data from your Cloud firestore or RTDB
Threading
Calls to data sources or repositories should be main safe therefore we should make the calls in suspend functions which enable us to launch coroutines. We should write main safe code for example where we are reading from a file or performing filtering operations on a large list.
If a class contains in-memory data which is critical to the entire app, then that class should be scoped to the application class.
Classes that contain data that are important for a particular flow should be scoped to a class that owns the lifecycle of that flow, e.g. activity, navigation graph.
Representing business models
It is good practice for the data layer to only expose data that the subsequent layers in the hierarchy require. For example, an api call might return data that is in excess of what is used within the app, in that scenario the data layer should be able to parse that data into a model that the app needs or uses.
For example;
// network article model
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
// App article model
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)This has some advantages like;
- Saves in app memory
- Adapts external data types to types that are used by your app.
- Provides better separation of concerns.
It is recommended to create a data class whenever the data sources return data that is not compatible with the app
Business oriented data operations like a user uploading their profile photo should survive process death. User WorkManagers to perform business oriented data operations.
Types of data operations
UI oriented operations; These are scoped to the UI.
App oriented operations; These are scoped to the lifecycle of the app.
Business logic oriented operations; These need to survive process death because they are critical to the value proposition of the app.
Handling errors
For coroutines and flows use kotlins built in error handling.
For errors that could be triggered by suspend functions, use try/catch blocks.
In flows, use the catch operator.
You can use a Result class to model the results from the data layer such that instead of returning just a type T we can return a Result which can contain data or an error message incase where it arises.
sealed class Resource<T>(val message: String? = null, val data: T? = null) {
class Success<T>(data: T?) : Resource<T>(data = data)
class Error<T>(message: String) : Resource<T>(message = message)
}Common Data Layer Operations
Fetching data from an API
Firstly we need to define a data source like below;
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val ioDispatcher: CoroutineDispatcher
) {
/**
* Fetches the latest news from the network and returns the result.
* This executes on an IO-optimized thread pool, the function is main-safe.
*/
suspend fun fetchLatestNews(): List<ArticleHeadline> =
// Move the execution to an IO-optimized thread since the ApiService
// doesn't support coroutines and makes synchronous requests.
withContext(ioDispatcher) {
newsApi.fetchLatestNews()
}
}
// Makes news-related network synchronous requests.
interface NewsApi {
fun fetchLatestNews(): List<ArticleHeadline>
}Relying on interfaces to abstract api calls can make implementations swappable in your app. Without updating the data sources.
Then we have to create a repository that exposes this data source to the other layers of the application
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
suspend fun fetchLatestNews(): List<ArticleHeadline> =
newsRemoteDataSource.fetchLatestNews()
}Now we can inject this Repository in a ViewModel and we can call the fetchLatestNews() function to get the news from the data source.
You can read more about the UI layer here:
Implementing in-memory caching
We can implement this for example when we need some data to persist across the lifecycle of the entire application.
For instance, we would like to show cached news first before fetching latest news from the api, this is an app oriented data operation.
Caches are meant to save some data in memory for a given amount of time. It can be in the form of a single mutable variable or a class that protects from read/write operations on multiple threads. Caching can be implemented in the repositories or data sources depending on the use case.
Caching the result of a network request
To protect a variable from read and write operations from different threads, a Mutex is used.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
// Mutex to make writes to cached values thread-safe.
private val latestNewsMutex = Mutex()
// Cache of the latest news got from the network.
private var latestNews: List<ArticleHeadline> = emptyList()
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
if (refresh || latestNews.isEmpty()) {
val networkResult = newsRemoteDataSource.fetchLatestNews()
// Thread-safe write to latestNews
latestNewsMutex.withLock {
this.latestNews = networkResult
}
}
return latestNewsMutex.withLock { this.latestNews }
}
}This operation caches the result of the network request to a Mutex therefore it is write protected from other threads. If the network request is successful the result is assigned to the latest news variable.
Network calls should be app oriented operations, for example to follow dependency injection principles a repository should receive a CoroutineScope as a parameter such that the repository class does not need to create a repository that is scoped to its lifecycle but the lifecycle of the app.
class NewsRepository(
...,
// This could be CoroutineScope(SupervisorJob() + Dispatchers.Default).
private val externalScope: CoroutineScope
) { ... }Therefore after making the network call, we can save the result using a new CoroutineScope that we start using the externalScope
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val externalScope: CoroutineScope
) {
/* ... */
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
return if (refresh) {
externalScope.async {
newsRemoteDataSource.fetchLatestNews().also { networkResult ->
// Thread-safe write to latestNews.
latestNewsMutex.withLock {
latestNews = networkResult
}
}
}.await()
} else {
return latestNewsMutex.withLock { this.latestNews }
}
}
} async is used to start the coroutine in the external scope.
await is called to suspend until the network request is received and the result is saved to the cache.
In this scenario if the user is still on the screen, they will see the latest news but if they are not or move away from the screen, then the await is cancelled but the logic inside async continues to run.
Saving and retrieving data from disk
Roomdatabase, this is for large datasets which need to be queried and need to maintain integrity. Such as news articles and authors.Datastore, this is for small data that will most likely just be set or retrieved infrequently like user preferences and settings. This is perfect for storing key value pairs e.g. time format, notification preferences. It can also store typed objects withProtocol Buffers. Datastore values are emitted as a flow whenever the values are updated, therefore it is advised to store related information in the same datastore for exampleNotificationsDataStore,NewsPreferencesDataStoreFilefor chunks of data like JSON, Bitmap. File reads should be thread safe.
Scheduling tasks using WorkManager
For example if we need an app to fetch latest news whenever the device is charging or connected to an unmetered network.
WorkManager makes it easy to schedule asynchronous work and also manage the constraints.
To perform a certain operation we need to create a Worker class that takes a Repository class and performs some operation like fetching data from the internet and persisting it to the local cache.
class RefreshLatestNewsWorker(
private val newsRepository: NewsRepository,
context: Context,
params: WorkerParameters
) : CoroutineWorker(context, params) {
override suspend fun doWork(): Result = try {
newsRepository.refreshLatestNews()
Result.success()
} catch (error: Throwable) {
Result.failure()
}
}The business logic for this kind of task should be encapsulated in its own class and treated as a separate data source. This makes implementations easily swappable.
WorkManager ensures the work completes successful on a background thread when all constraints are met.
private const val REFRESH_RATE_HOURS = 4L
private const val FETCH_LATEST_NEWS_TASK = "FetchLatestNewsTask"
private const val TAG_FETCH_LATEST_NEWS = "FetchLatestNewsTaskTag"
class NewsTasksDataSource(
private val workManager: WorkManager
) {
fun fetchNewsPeriodically() {
val fetchNewsRequest = PeriodicWorkRequestBuilder<RefreshLatestNewsWorker>(
REFRESH_RATE_HOURS, TimeUnit.HOURS
).setConstraints(
Constraints.Builder()
.setRequiredNetworkType(NetworkType.TEMPORARILY_UNMETERED)
.setRequiresCharging(true)
.build()
)
.addTag(TAG_FETCH_LATEST_NEWS)
workManager.enqueueUniquePeriodicWork(
FETCH_LATEST_NEWS_TASK,
ExistingPeriodicWorkPolicy.KEEP,
fetchNewsRequest.build()
)
}
fun cancelFetchingNewsPeriodically() {
workManager.cancelAllWorkByTag(TAG_FETCH_LATEST_NEWS)
}
}These classes are named after the data they are responsible for like NewsTasksDataSource and PaymentsTasksDataSource All tasks related to a particular type of data should be encapsulated in the same class.
If the task needs to be triggered at app startup, it’s recommended to trigger the WorkManager request using the App Startup library that calls the repository from an Initializer.
For classes that communicate with external resources, it is helpful to implement interfaces for them.
